SceneLine: AI-Powered Dubbing Practice Platform
SceneLine: AI-Powered Dubbing Practice Platform 🎬
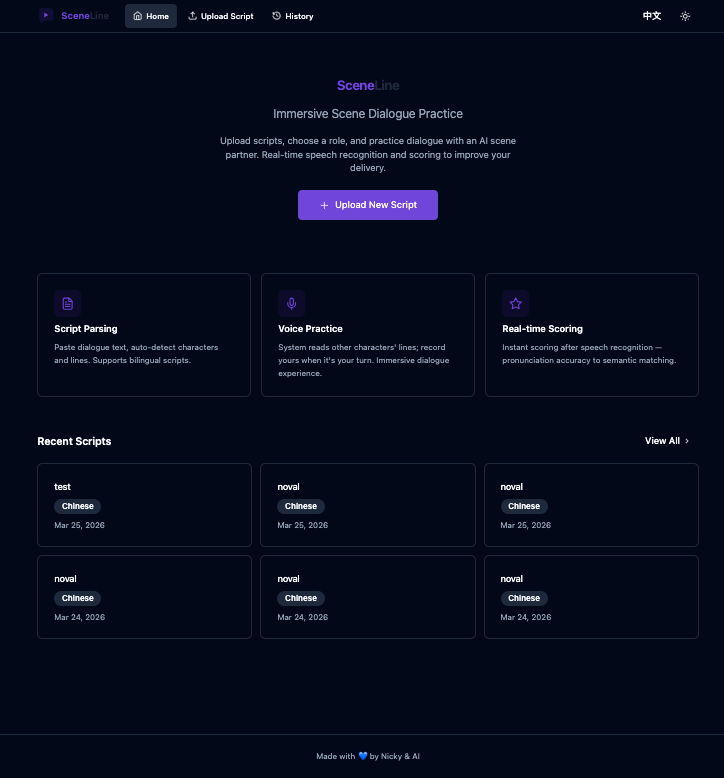
I recently released a new project called SceneLine — an AI-powered dubbing practice platform that enables language learners to practice dubbing through immersive film/TV scene dialogues.
Why I Built This
The hardest part of language learning is often not vocabulary or grammar, but language sense — that natural, authentic way of expression. Traditional listening and reading exercises struggle to develop this, but dubbing practice is a great solution:
- Immersive scenarios — Real movie/TV dialogues, not textbook sentences
- Multi-character interactions — Different tones, emotions, and pacing
- Instant feedback — Know whether your pronunciation is accurate
But traditional dubbing practice has a pain point: no feedback. You say the lines along with the video, but don’t know if you’re doing it right.
SceneLine aims to solve this.
Core Features
🎙️ Real-time ASR (Speech Recognition)
- Uses FunASR for speech recognition
- Resident process mode, 10x performance optimization
- Real-time comparison of your pronunciation against the original
🔊 40+ TTS Voices
- Microsoft Edge TTS support
- 40+ voice options
- Filter by gender/locale to find the best reference voice
🎭 Multi-character Dialogue Practice
- Supports multi-role scenes (like Friends dialogues)
- Individual scoring for each character
- Practice multiple roles by yourself
📊 Practice History & Statistics
- Three view modes: Overview / By Script / Details
- Track your progress curve
- Identify weak areas
📝 Smart Deduplication
- Content hash-based script deduplication
- Automatically merges identical content to avoid repetition
Tech Stack
Frontend
- React + Vite — Fast development experience
- Tailwind CSS — Clean UI design
- TypeScript — Type safety
Backend
- Express + TypeScript — API service
- FunASR — Core speech recognition
- node-edge-tts — TTS wrapper
AI/ML
- FunASR — Alibaba DAMO Academy’s open-source ASR framework
- ModelScope — Model hub
- faster-whisper — Accelerated Whisper ASR
Quick Start
One-click Launch (Recommended)
git clone https://github.com/hugcosmos/SceneLine.git
cd SceneLine
./start.sh
First launch will:
- Ask if you’re in mainland China (auto-configures mirror sources)
- Download ASR model (~2GB, takes 6-9 minutes first time)
Then visit http://localhost:5000
Docker Deployment
docker-compose up -d
System Requirements
- Node.js: 20+
- Python: 3.9-3.11 (ASR dependencies, torch doesn’t support 3.12+)
- Memory: Minimum 4GB (ASR model uses ~2GB)
- Disk: 3GB+ free space
- FFmpeg: For audio format conversion
Project Structure
sceneline/
├── server/ # Backend (Express + TypeScript)
│ ├── lib/ # Core libraries (ASR, TTS)
│ └── routes/ # API routes
├── client/ # Frontend (React + Vite + Tailwind)
│ └── src/pages/ # Page components
├── shared/ # Shared type definitions
├── models/ # ASR model cache
├── tts-cache/ # TTS audio cache
└── docker-compose.yml
License
MIT License — Fully open source, contributions welcome.
Future Plans
- Multi-user mode — Support multiple users practicing simultaneously with real-time comparison
- Streaming ASR — Faster real-time recognition with lower latency
- Intelligent scoring system — More systematic and human-friendly scoring mechanism
- TTS upgrade — Support for richer voice options
- Multiple TTS providers — Integration with more API providers (ElevenLabs, iFlytek, Baidu, etc.)
Links
- GitHub: github.com/hugcosmos/SceneLine
Made with 💙 by Nicky & AI